

Featured image: Couldn’t resist the cuteness. Image taken from Pixabay
Have you come across scientific studies that produced opposing conclusions on the same topic? Are carbohydrates responsible for weight gain? Does the pesticide glyphosate cause cancer? Does Prozac effectively treat depression? Scientists are examining the same issue and coming up with radically different results. Honestly, what should you believe!?
To answer this, we need to understand why conflicting results happen and how to interpret them.
Why do we see conflicting results?
There are several reasons for conflicting results, including: a) biases, b) choice of test subjects, c) faulty statistics, and d) a sloppy peer review process.
Scientists may unwittingly produce biases when they are conducting experiments and writing papers. For example, they may not randomize for sex of animals in control and treatment groups or they may unconsciously mishandle rats that they know were treated with a harmful substance. Also, scientists may publish or share data selectively, for instance by under-reporting results that do not support their hypothesis. If steps are not taken to address these biases, scientists may produce incorrect results.
Then there are problems with test subjects. In some cancer studies, mice and rats show similar results only 35 to 37% of the time. So, it may not be always wise to compare data that were generated from different species. Also, thousands of papers have been published using cell lines that have been contaminated or misidentified (for example, pig cells were passed off as human cells), and little effort has been made to retract these invalid results.
Statisticians found that only 34% of papers published in medical journals got their statistics right. And scientists sometimes incorrectly use correlation data (i.e., A changes similarly to B) to establish a causal link (i.e., B causes A), even though correlations can be found between factors that are clearly unrelated. People without a strong statistics or science background may take these studies at face value.
Also, the peer review process, where independent researchers assess the validity of a manuscript prior to its publication, often fails to do its job by not weeding out badly designed or low-quality studies. Given all this, it is little wonder that a researcher could only confirm the findings of 6 out of 53 ‘landmark’ cancer papers.
It has also been observed that funding sources can correlate with the outcome of some studies. This is why it is important to mention all funding sources and potential conflicts of interest when publishing a paper. It will help others independently evaluate the results and conclusions of the study. And, whenever possible, all scientists should make efforts to share their raw data so that others can accurately replicate their study or reanalyze their statistics.
Since I have spoken a lot about some of the problems facing scientific research, I think it is important to end this section by stressing that conflicting results are not the norm – scientists have often come to unanimous decisions on several topics.
How to interpret conflicting results?
We frequently cannot draw broad conclusions on an issue from a single study. This is why review papers are important; they condense and evaluate information from multiple individual research papers. But a lot of review papers have unfocused or broad topics and the reader does not know why only some studies were analyzed and how the authors judged the quality and importance of individual studies. This can result in review papers producing different conclusions even though they ask the same question and have access to the same database. To give an example, 29 researchers assessed the same database to see if trichloroethylene could cause cancer. Four researchers said the compound was carcinogenic, six said it was not. The remaining 19 were unsure.
Scientists are thus moving towards systematic reviews, which involves asking specific questions and having a clear and unbiased criterion for selecting studies. The authors should justify why certain studies were excluded (for example, did they not fulfill the criteria for selection? Were they outside the scope of the research question?) and score the quality of included studies (by checking if all details of the study were provided, if biases were avoided, if the methods were sound). To account for personal biases, at least two scientists should independently determine which studies should be included in the review and what scores to assign the selected studies. Then, when a consensus is achieved, studies whose qualities are deemed acceptable are further analyzed to integrate the findings. This is called meta-analysis.
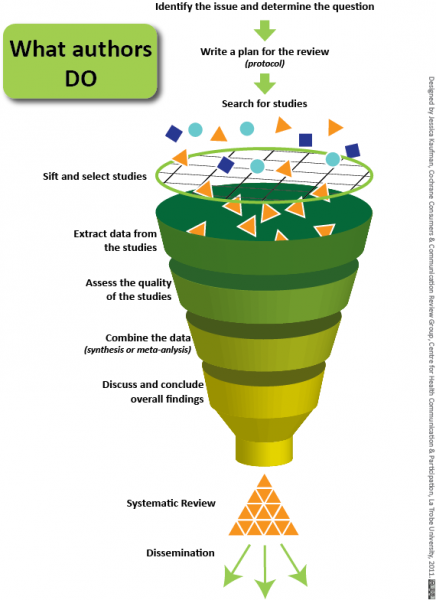
Meta-analysis typically involves gathering information from the chosen studies (like the number of participants, effect of the treatment, variability in results, etc.) and pooling them to come to a conclusion. Studies with a higher quality score are given more weight. Pooling of individual studies increases the overall sample size, and this increases the power (or ability) to detect a difference between control and treatment groups. For example, in the 1980s, scientists were unsure if beta blockers (drugs that reduce blood pressure) were effective at treating heart attacks. This is because single studies had very few significant results and large variability in the data. But when the studies were combined, the sample size increased and the variability decreased, and the data clearly showed that beta blockers can be used to successfully treat heart attacks.
What does this mean?
Systematic reviews and meta-analysis are great tools to analyze multiple studies and draw a more accurate conclusion. They are transparent, unbiased, and allow scientists to assess every study’s validity and quality. Their use originated in the field of medicine, but now scientists are increasingly using it in other fields like toxicology (evidence-based toxicology).
Next time you are looking for information on a controversial topic, remember to first search for papers that use these methods!
